This assignment’s objective was to identify the predictors of Data Scientists (and other related titles) salaries, practicing web scraping, data cleaning and predictive modeling skills.
The outcome of this project was to build an accurate model to predict high or low salaries, and denote which features were the most predictive.
The Data Source and Methodology
Results from Indeed.com were pulled using the search term, “Data Scientist”.
All job postings were scrapped from a total of 11 cities around the US. These cities were: New York, San Francisco, Austin, Seattle, Boston, Raleigh, Charlotte, Chicago, Portland, New Orleans, and Denver.
Please note that these terms and locations were directly inputted into Indeed.com’s search engine - therefore, not all results were exclusive to “Data Scientists” (e.g. “Data Engineer” would appear) or the specific location (e.g. “Research Triangle in NC” would appear). Surrounding locations were amended to be rolled into its larger metro area.
3 factors were identified that could potentially predict a salary:
- Location: which of the 11 cities were the most predictive?
- Title: do words like “senior”, “engineer”, “analyst”, “statistician”, “specialist” or “manager” in a title make a difference in salary?
- Company: do companies in the education, healthcare or government predict a salary?
Annual salary (all non-annual rates were removed) was the target variable (203 total values). Rather than predict the exact salary amount, salary was analyzed as “High” (above the median value of $117,234) or “Low”. This was to account for the wide range of potential salaries across various locations in the US.
The Model
The final model that was chosen was a Logistic Regression with a L2 penalty and a C value of .01, using all 3 of the above listed factors, to reach an accuracy score of .67.
In other words, this model that suppressed the impact of each of the different factors that were chosen, compared to other modeling techniques.
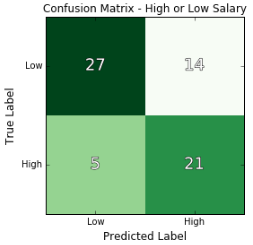
The result had a relatively high average precision score of .74, and an average recall of .72:
The Predictive Factors
With a model, predictive factors can be determined by evaluating the coefficients of each factor. A relatively high positive coefficent means that the factor is positively correlated with a higher salary.
For our analysis, this meant that:
- Location: San Francisco is the most correlated
- Title: “Senior” is the most correlated
- Company: Companies NOT in the education, healthcare or government industry are the most correlated
San Francisco likely has the highest salary for Data Scientists because of its mature tech industry, relative to the rest of the other chosen cities.
It is interesting that “Senior” over other titles like “Manager”, was the most salient out of all the other words. This likely represents that the Data Science field is still a nascent industry, with not many senior-level titles.
Also, it is unsurprising that companies not in education, healthcare or the government would have the highest pay. This is likely because industries outside of these fields are in the private sector, and thus would pay more.
Closing Thoughts
The current model produced results with relatively high accuracy scores, with results that make intuitive sense.
The biggest hinderance to this exercise was the volume of job listings with annual salaries. Its quite rare for a job listing to list out a salary, let alone an annual one. Out of 5,186 postings that were scraped, only 203 had an annual salary. This means that only 3% of the entries had a usable salary. Further builds could be done to expand this sample size, to help create an even more predictive model.
As this was an initial dive into making a predictive model, more features using NLP could definitely be added to build upon this model.